SQL Panel¶
Every tabular file you open in Octa is queryable via SQL. The active
table is exposed to an in-memory DuckDB connection as a temp table
called data. Press Ctrl+Enter in the editor and your query runs
against the loaded rows.
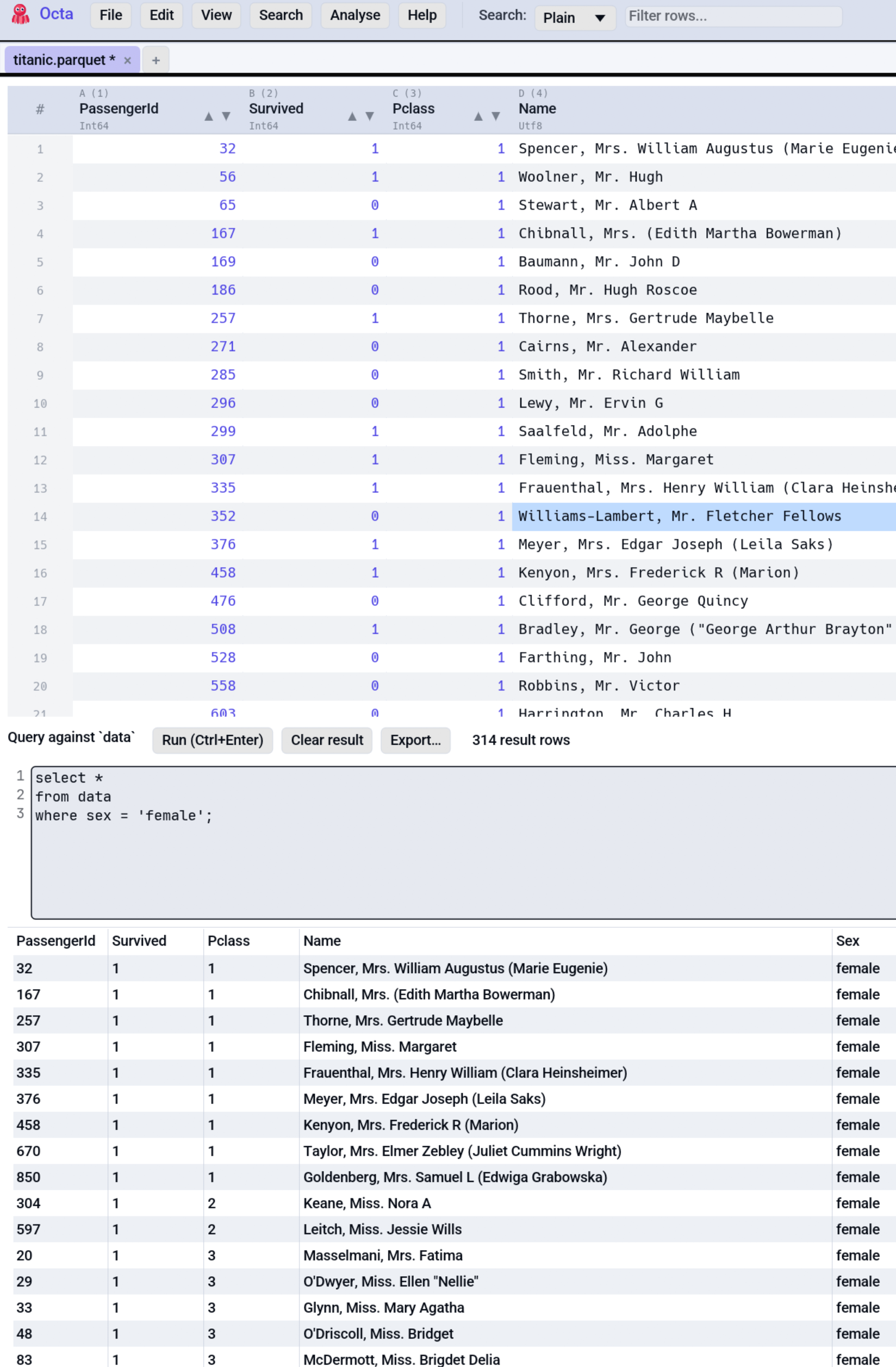
Opening the SQL panel¶
Three ways:
- Analyse → SQL in the toolbar (visible when the active tab is on a tabular file in Table view).
- The
ToggleSqlPanelshortcut (default Ctrl+J). - Auto-open on file load via Settings → SQL → Open SQL panel by default.
The panel docks to the bottom by default. Change the side under Settings → SQL → Panel position (Bottom, Top, Left, or Right). The SQL panel is independent of the Chart tab; the Analyse menu also opens a chart in a new tab, and the two features can be used together.
Writing a query¶
The editor is a multi-line TextEdit with:
- Line numbers in a left gutter (greyed out, monospace).
- Monospace code throughout, defaulting to JetBrains Mono bundled with Octa. Switch to system monospace or match-UI font under Settings → SQL → Editor font.
- Right-click menu for Copy
Autocomplete¶
When the caret sits at the end of a word token, Octa shows a row of chip-style suggestions beneath the editor, listing matching column names and SQL keywords. Click a chip to insert, or drive the popup from the keyboard: Up / Down move the highlight, Enter or Tab accept the highlighted suggestion, Esc dismisses it. These keys are only intercepted while the popup is open, so with no suggestions showing Enter and the arrows behave normally. Disable under Settings → SQL → Autocomplete.
The editor also takes keyboard focus the moment the panel opens, so you can start typing immediately without clicking into it first.
Running a query¶
- Ctrl+Enter runs the entire query.
- A Run button in the toolbar does the same as Ctrl+Enter.
- A Clear button empties the editor.
Each run creates a fresh DuckDB connection, so there is no
persistent SQL state between queries. Accidental mutations therefore
do not accumulate across runs; an UPDATE in one query does not
carry over to the next.
History and snippets¶
The SQL toolbar has two ways to reuse queries:
- History is a dropdown listing the recent queries run in this tab, most recent first. Pick one to load it back into the editor. History is per tab and session-only (it is not saved to disk).
- Snippets opens a manager window for a persistent, named library
of queries. Save current query as snippet... stores the editor
content under a name and an optional description; each saved snippet has
Insert (load it into the editor) and x (delete). The window has
the usual minimise / maximise / close controls and is resizable.
Snippets are stored in
sql_snippets.jsonin the config directory, so they survive restarts and are shared across all tabs.
What's available¶
DuckDB's full SQL surface, including:
- Window functions:
ROW_NUMBER(),RANK(),LAG(), etc. - Aggregations:
SUM,AVG,COUNT,MEDIAN, percentiles, etc. - JSON functions:
json_extract,unnest, … - Date/time functions, string functions, regex functions.
- CTEs (
WITH ... AS (...)), subqueries, correlated subqueries. PIVOT/UNPIVOT.DESCRIBE datato see the column types DuckDB sees.
The placeholder query shown when the editor is empty is
SELECT * FROM data LIMIT {settings_default} (the default row
limit is configurable under
Settings → SQL → Default row limit).
This is only a hint; your editor field is actually empty, so type to
replace.
Result rendering¶
Results render in a table below the editor. The result table is a
separate egui_extras::TableBuilder from the main
Table view (no edit overlay, no row selection
beyond click-to-select-text).
Errors render in red below the editor.
Mutations¶
INSERT / UPDATE / DELETE queries run via conn.execute()
instead of conn.query(). After a mutation, Octa re-selects the
full data table and replaces the base table in the active
tab, so the mutation's effect is visible immediately.
To make the effect easy to spot, Octa briefly highlights the changed cells and any new rows in green after a mutation. Toggle this and set its duration under Settings → SQL (Highlight SQL changes / Highlight duration, on by default, 4 seconds). The highlight is a temporary display mark and clears itself.
Mutations don't persist back to disk by default
The in-memory DuckDB connection is recreated on every Ctrl+Enter, so any mutation is lost when you close Octa unless you also save the file via File → Save.
For files Octa supports writing (CSV, Parquet, SQLite, …), saving after a mutation persists the change. For read-only formats (SAS, HDF5, …) the change is in-memory-only, though you can Save As to a writable format to export it.
Exporting results¶
The toolbar's Export… button (and the Ctrl+Shift+E shortcut) saves the current SQL result as a separate file. The dialog accepts any writable format Octa supports: Parquet, CSV, JSON, SQLite, etc.
Examples¶
-- Count rows per category
SELECT category, COUNT(*) AS n
FROM data
GROUP BY category
ORDER BY n DESC;
-- First / last per user
SELECT user_id,
MIN(timestamp) AS first_seen,
MAX(timestamp) AS last_seen
FROM data
GROUP BY user_id;
-- Rows containing JSON
SELECT id, json_extract(payload, '$.user.email') AS email
FROM data
WHERE payload IS NOT NULL;
-- Window function: rolling 7-day count
SELECT date,
COUNT(*) OVER (
ORDER BY date
RANGE BETWEEN INTERVAL 6 DAY PRECEDING AND CURRENT ROW
) AS rolling_7d
FROM data;
-- DESCRIBE for schema discovery
DESCRIBE data;
Limitations¶
- One table per session. Only
datais registered, so there is no way to JOIN across two open tabs from the GUI yet (useocta --sqlwith two files, or copy-paste the relevant data). - No DDL persistence.
CREATE TABLE other AS SELECT ...succeeds but the new table dies with the connection on the next Ctrl+Enter. - No extensions yet. DuckDB has powerful extensions
(
spatial,postgres_scanner,sqlite_scanner, etc.), but they are not auto-loaded by the SQL panel.
For multi-file analysis the CLI's
octa --sql FILE -q 'SELECT ...' is a good
companion: it spins up a fresh DuckDB and you can layer ATTACH /
COPY however you want.
See also¶
octa --sqlis the CLI form of this panel.- Settings → SQL covers autocomplete, panel position, default row limit, and editor font.
- Search & Filter covers value-based filtering that does not need SQL.
- Chart opens the active table in a new chart tab from the same Analyse dropdown.